Transforming data for API-Driven Inbound Provisioning using Azure Data Factory
Maintaining accurate and up-to-date identity information across various systems of record and Entra ID is crucial for seamless identity lifecycle management, enhanced security, and regulatory compliance.
Whether migrating from Microsoft Identity Manager (MIM) or starting fresh, Microsoft Entra ID inbound provisioning is simplified using the bulkUpload API endpoint. However, inbound provisioning often requires intricate manipulation and enrichment of source data – something MIM does well – to ensure accurate representation within Microsoft Entra.
Managing the transformation and enrichment of data, such as standardizing data formats, maintaining unique attributes, and adding additional information like contact details, job titles, or organizational hierarchy through lookups, poses significant challenges.
Azure Data Factory (ADF) offers a robust solution to bridge this gap. ADF enables the extraction, transformation, and enrichment of data. With ADF you can ensure that the data is clean, complete, and correctly formatted before Microsoft Entra inbound provisioning, facilitating smoother and more effective identity management.
API-driven inbound provisioning
Microsoft Entra ID supports inbound provisioning from any system of record, such as HR systems or payroll applications, through the bulkUpload API endpoint. This affords an extensible platform to build inbound provisioning where scoped data is brought into Microsoft Entra and transformed using simple attribute mapping rules. Lifecycle workflows can also be used to map the business Joiner-Mover-Leaver (JML) processes, thereby providing a mechanism for accurate and up-to-date identity information.
Options for uploading data
At the time of writing, Microsoft’s documentation on API-driven inbound provisioning (API-driven inbound provisioning concepts – Microsoft Entra ID | Microsoft Learn) describes three supported scenarios:
- Automation tool(s)
- HR vendor-supported direct integration (using SCIM 2.0)
- Custom HR connectors
Considering the second scenario, we are not aware of any HR main-stream application currently providing out-of-the-box support for this. Scenario three could be an option. We could build a custom HR connector to read the data, but it places an additional burden on the HR department as additional HR data is required to facilitate the custom connector development. Typically, HR teams are often too busy to assist with this outside of their normal scope of work – internal teams often have a large backlog of work to do, and if the HR system is outsourced, the additional costs may prove too significant.
This leaves the customer or partner to develop an automated tool.
Using an automated tool
Two of the most commonly used tools for automation are PowerShell and Logic Apps – and Microsoft provides examples of both, which is a good starting point:
- A PowerShell script to upload data from a CSV file
- A Logic App to upload data from a CSV file in Azure Blog Storage
Why is more needed?
There are a variety of requirements and tasks to consider when we move from a basic demo or proof-of-concept to something suitable for production, for example:
- Extracting the data from the system of record
- Data cleanup
- Unique name generation (e.g. User Principal Names and email addresses)
- Performing lookups or calls for additional data such as department codes /names, or location codes/ addresses
- Implementing a paging mechanism for the bulkUpload API endpoint, which supports a maximum of 50 records per request
- Using deltas to avoid limits and performance issues – there are limits on the number of records that can be uploaded per day (depending on your license) and deltas can help to avoid hitting this limit or to enhance performance
- Handling precedence – if a user is present in two Systems of Record which one “wins”?
Of course, a PowerShell script is extremely flexible, and with the right development all the above scenarios can be catered for, but this requires someone with advanced PowerShell coding skills.
A code-less solution may be more appealing. Depending on the requirements this may be possible with a Logic App (potentially with other supporting Logic Apps or Azure functions). Another approach is to use Azure Data Factory (ADF) to do the heavy lifting of extracting and transforming the identity data and an Azure function or a Logic App to perform the final upload step.
Introducing Azure Data Factory (ADF)
ADF is a cloud-based, code-free data integration service that orchestrates and automates data movement and transformation workflows. It is designed for large-scale extract-transform-load (ETL) operations, and we can take advantage of its inbuilt connectors and data flows to pre-process and augment our identity data (performing advanced data transformations) before sending it to Entra ID.
Example scenario
Consider an HR data source (which happens to be a SQL table, but could be any source) as the authoritative source of employee data. In our scenario, the HR system provides an employee ID which we will use as our anchor, but it doesn’t hold unique values for UPNs so we will have to generate and store these (as the UPNs are not written back from Entra ID). In addition, deltas are not supported so we also need to build in functionality to address data load and performance.
To achieve this, we can:
- Create an ADF pipeline to extract the data, transform it, and populate a staging table
- Use a Logic App to call a stored procedure in the staging table database to process deltas or the full data set
ADF pipeline
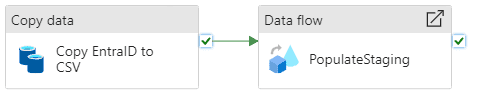
An ADF pipeline containing two steps is required:
- A copy data activity to extract a list of users with their UPN from Entra ID for performance optimization (avoiding the need to look up each user during the data flow)
- A data flow activity to transform the data and populate the staging table
ADF data flow
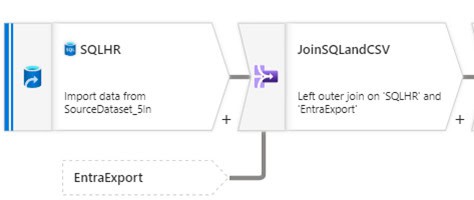
A data flow activity to:
- Extract the data from the HR SQL table and Entra ID CSV file
- Join the two sources together and create a new derived column for the UPN
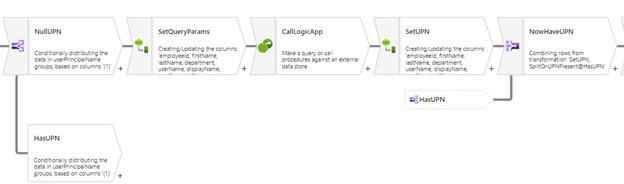
- Conditionally (split task) generate a UPN, if not already populated, generate the unique UPN using a Logic App (an Azure function or web service would work equally well)
- Join the two streams back together
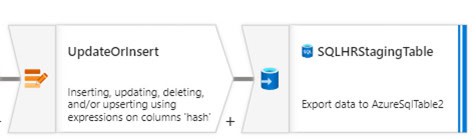
- Calculate and compare data hashes (staging table) to determine if updates are needed (adding IsUpdated column data)

- SQL Insert (new user) or update, to populate the staging table




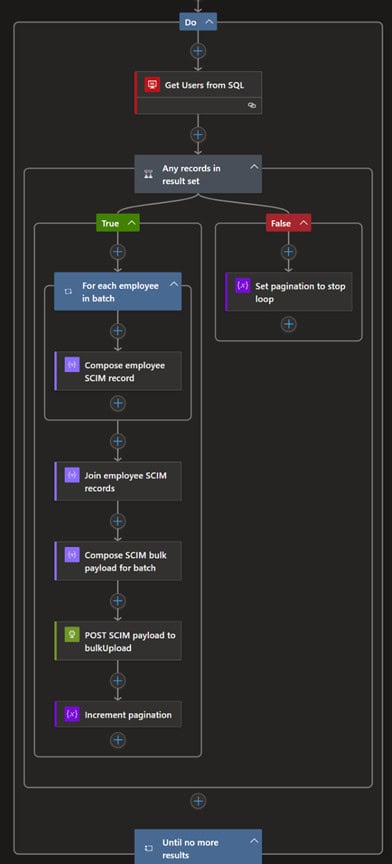
Logic App
In our example, the Logic App repeatedly calls a stored procedure getting up to 50 records a time, constructs a JSON document, and POSTs it to the bulkUpload endpoint.
Azure Data Factory costs
ADF is priced on resource consumption rather than per-user licenses:
- Orchestration and Execution – number of activity runs
- Data Flow – CPU time used
- Data Factory operations – number of read/write operations.
For example, running a pipeline (trigger and run an activity) every hour over 30 days (1,440 runs) that takes 10 minutes per run (120 hours) and performs 20,000 reads and writes, costs approximately $275 a month.
Conclusion
ADF provides a cloud-based, code-free, and cost-effective solution for anyone looking to manipulate and enhance source data before inbound provisioning to Microsoft Entra ID. Using ADF to perform advanced data transformations and provide additional features, such as calls to external systems, merging data sources, and handling precedence and deltas – which are not available in Microsoft Entra ID (yet!) – is easily achievable.
Need help?
Contact us if you would like more information or assistance using ADF.
At Oxford Computer Group, we specialize in helping clients across industry sectors move from MIM to a cloud-first identity model. With decades of experience in MIM, we understand the intricacies of user provisioning and how to navigate the transition.
- Request a MIM Migration Design Workshop. We evaluate your current setup and provide a tailored design specification report for your best migration path from MIM
- Explore our insightful articles
- Watch our webinar ‘Transitioning from MIM to Microsoft Entra cloud-first IAM’
- Watch our webinar ‘Moving from MIM to Microsoft Entra ID Governance’
- Talk to us about how we can support your MIM implementation, so your team can focus on the migration
- Contact us to discuss your next steps